| 当前位置: 电脑软硬件应用网 > 设计学院 > 网页设计 > 正文 |
|
|||
| SEO:有效的进行外链的优化工作 | |||
| 2011-9-18 10:25:57 文/佚名 出处:网页教学网 | |||
|
如果说SEO的工作就是服务搜索引擎的话,那么对外链的优化就是服务搜索引擎的SPIDER模块,SPIDER如果通过大量链接爬取到你的网站那 么他可能就会判断出你可能是这些网页中的一个信息节点,信息的来源,从而给你一个相当的权重。这个是外链对于搜索引擎的意义同时也是对于SPIDER的意 义。 我们先来看看SPIDER的工作,SPIDER作为一台服务器从互联网某个信息节点开始抓取网页信息回传到数据库。互联网的一开始网站以综合信息为 主,所以SPIDER工作相对简单,整个搜索引擎的排序机制也相对简单。但是随着互联网的发展互联网的信息被不断的细分,SPIDER的工作也被变得复杂起来。搜索引擎为了能够快速的展示搜索结果页面必须对数据进行同样的信息细分,SPIDER从一开始的单一抓取又增加了一个信息分类的功能,但是当信息分类上升到千万这个级别的时候整个信息抓取再分类的过程就变得冗长且缓慢。最根本的解决方法就是在SPIDER抓取前就为服务器定义分类,即特定的 SPIDER服务器只抓取某几类的信息内容,这样分类就变得简单且快速。SPIDER又是如何在抓取前就定义自己的抓取路径呢?我们可以建立这样的一个工作模型。 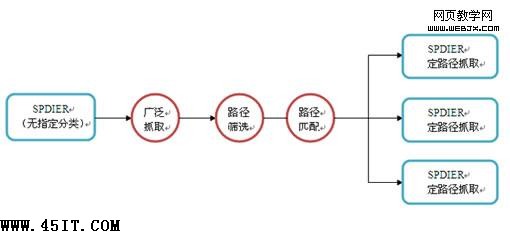 这个流程很容易理解,对我们最为重要,也是最需要了解的一个环节那就是路径筛选。SPIDER是如何进行筛选的,用一个模型建立的逻辑来考虑这个问 题就是,当一个模型没法进行试验的话,首先确定模型中两个以上不辩自明的公理,再由这两个公理进行逻辑推导。我们就先要确定的公理 第一:保证整体运转的效率。第二:保证抓取内容与分类的匹配。 这样通过逻辑推导我们可以设想出这样一个工作原理:泛抓取SPIDER抓取的路径通过分析(分析过程类似于路由器寻找节点间的最短路径)。分析要得 出的将是一条由链接组成的抓取路径,路径中所抓取到的页面信息都是属于同一分类的信息,然后计算路径长度得出最优路径,最后将最优路径筛选的出后提交到定 抓取的SPIDER服务器,接着定抓取的SPIDER服务器就能按照这条路径进行快速的抓取和分类了,并且再下次泛抓取服务器更新最优路径前都是按照这个 路径进行抓取。 举个例子的话就好比:在一座果园中均匀且分散了红苹果和青苹果,现在果农需要采摘苹果并且按照红苹果和青苹果分类贩卖。一开始果农按照顺序把所有的 苹果全部摘下来,然后再进行分类包装。后来为了提高效率,果农开始在把果树画在纸上,把所有的青苹果树用线连在了一起,把红苹果树用线连在一起,然后分成 两批人按照两种不同的路线去采摘,采完后就直接装包贩卖。 那么在了解到这个筛选机制后我们能够做出怎样的外链策略呢? 友情链接,外链所在的页面和自己网站内容相关 外链所在的页面导出的链接指向的页面绝大多数也需要和自己网站相关 避免和拥有大量外链的网站进行交换(就好比一个房间如果出口只有一个,那你能很快的判断出如何出去,但是一个房间有上百个出口,你了解完这些出口分别通向哪里就需要很长的时间,极大的降低SPIDER效率) 避免和大量有与其网站不相关的外链网站进行链接 不要让你的网站一个导出的链接都没有,实在没有外链也宁可链接到一个权重高的相关网站也比不做导出链接更受SPIDER喜爱 以上这些可能是最基本的一些推导出的结论。根据这个筛选规则,我们甚至可以自己制作一个让蜘蛛循环抓取的路径提供给搜索引擎,这个循环路径的表现形 式,就是现在越来越被大家采用的链接论模式,将外链形成一个内容相同的环让SPIDER不断的抓取路径上的所有网站提升路径上网站的权重。 当然通过这样的一个结论模型一个有创造力的SEO还能创造出各种优化手段,这里就需要大家自己去慢慢琢磨了。 如果 你耐着性子看完了上面所有的文章,那么再想一想,现在自己在做的外链是不是会有些盲目和低效呢~自己之前真的懂得如何有效的做外链么?还是只知道如何快速的做大量的外链~ |
|||
| 最新热点 | 最新推荐 | 相关阅读 | ||
| 关键词匹配的形式,关键词匹配的小常 网站更快:开启gzip和deflate压缩 用标题来提高网站流量的常用手段 全方位解析内部链接构造 十个让你获得高枕无忧外链资源的方法 四招避免网站降权 网站站长应该知道的:Google+1按钮 网站的一般seo策略介绍 最好的SEO方法是为网站流量而建立内 网站优化时不容忽视的五大细节 |
| 关于45IT | About 45IT | 联系方式 | 版权声明 | 网站导航 | |
|
Copyright © 2003-2011 45IT. All Rights Reserved 浙ICP备09049068号 |