| 当前位置: 电脑软硬件应用网 > 电脑学院 > 操作系统 > Linux系统 > 正文 |
|
||||
| Unix/Linux系统自动化管理:数据备份与同步篇 | ||||
| 2009-8-25 16:04:24 文/网络收集 出处:电脑软硬件应用网 | ||||
|
数据是 Unix/Linux 系统中最重要的组成部分 , 但是数据的备份与同步却是最容易被忽略的任务。通过定期的数据备份与同步,可以在磁盘出现故障时,最大程度的降低数据损失。当用户误操作导致数据损坏或者丢失时,可以快速恢复。
•系统信息:系统用户,组,密码,主机列表等。 •应用程序:系统上启动的服务,比如 web 应用程序,apache 等。 •应用程序的配置文件与数据:针对不同的应用程序,不同的配置参数和重要数据文件。 •数据库:事实上数据库可以单独提供针对数据库所有数据的备份与同步功能。 简单的数据备份是指一次性备份所有数据,然后再备份上次备份之后所做的修改。第一次备份是指“完全备份”,后一次备份是“增量备份”。通常适用于个人或者小型网站。对于机构或者大型网站来说,需要采用“多级备份”。将完全备份设定为 0 级,增量备份的级别分别是 1,2,3 等。在每个增量备份级别上,可备份同级或上一级的上次备份以来的变动。
磁带 3-6, 周备份,每周星期五(排除第一周) 磁带 7-10,日备份,每周星期一到四,则可以将备份历史扩展到两个月。
要创建 /CriticalData 的存档文件,使用:
将 /CriticalDate 目录和它的所有文件和子目录建立存档,使用:
cpio 建立起来的归档文件包括文件头和文件数据两部分。文件头包含了对应文件的信息。如文件的 UID,GID,连接数以及文件大小等。其好处是可以保留硬连接,在恢复时默认情况下保留时间戳,无文件名称长度的限制。
•基本操作系统安装镜像 •虚拟目录 (TOC) •rootvg 上的实际数据 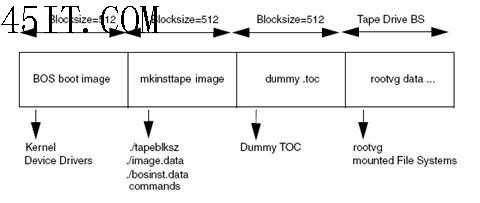
mkinsttape 镜像包括以下重要文件:
•Tapeblksz 该文件包含运行 mksysb 前设置的磁带驱动器的块大小。 •bosinst.data 该文件指定目标系统的需求以及基本操作系统安装程序是怎样运行
•image.data 该文件包含安装过程中实际安装的镜像的描述数据(文件大小、名称、装入点等)。
表 3. mksysb 命令的常用参数: 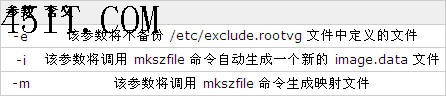 在运行 mksysb 前,可以运行 mksysb -i 命令来自动生成一个新的 image.data 文件。虚拟 TOC 可以确保 mksysb 磁带中包含的镜像数与基本操作系统安装磁带中的镜像数相同。最后,rootvg 数据包含用 mksysb 命令备份的实际数据。它实际上会使用 backup 命令保存 rootvg 中所有装入的文件系统的内容。
如果对用户卷组进行备份的话,可使用下列的命令:
# savevg -if /dev/rmt0 uservg
其中,-i 参数将调用 mkvgdata 命令;-f 参数将数据存储到指定设备或文件中。
backup 介绍
backup 是 AIX 系统提供的一种备份文件和文件系统的方法,其本身就可以支持增量备份和多级备份,不必借助其它方式,其好处在此不在赘述。
表 4. backup 命令的常用参数:
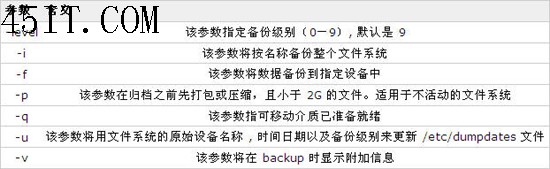
将 /CriticalDate 目录和它的所有文件和子目录备份到指定设备,使用:
# find /CriticalDate -depth | backup -i -f /dev/rmt0
将-level 和 -u 参数结合,可以进行多级和增量备份:
# backup -0 -uf /dev/rmt0 /home
rsync 介绍
如果将数据备份与远程传输结合起来,譬如 scp,就可以实现数据的远程备份。但通常的备份方法,都无法对本地和远程目录中的内容进行同步。
rsync(Remote Sync)是 Unix/Linux 系统下一款优秀的数据备份与同步工具。它可以对文件集进行同步。然而更有价值的是,rsync 使用文件的增量,也就是说,它在网络中仅发送两个文件集合有区别的部分。这样可以占用更少的带宽,并且速度更快。
rsync 的特性:
•能够更新整个目录树和文件系统 •保持原文件的权限,时间,软硬链接 •安装无需特殊权限 •优化的流程,文件传输速率高 •可以通过直接的 socket 连接传输文件,或者选择 rsh,ssh 等方式 •支持匿名传输 表 5. rsync 命令的常用参数:

如果在客户端对服务器上的重要数据进行备份的话,可使用下列的命令:
清单 1. rsync 命令演示
#rsync – avzP rsync@Server::CriticalData /Backup
=========================== This is Critical Data Server ===========================
receiving file list ... 9 files to consider Location/ Location/Locationlist1 97164953 13% 1.11MB/s 0:08:57
706609152 100% 1.17MB/s 0:09:37 (xfer#1, to-check=5/9) Name/Name1 44 100% 0.16kB/s 0:00:00 (xfer#2, to-check=3/9) Name/Name2 22 100% 0.08kB/s 0:00:00 (xfer#3, to-check=2/9) Time/Monday 17 100% 0.06kB/s 0:00:00 (xfer#4, to-check=0/9)
sent 32111 bytes received 497214837 bytes 847820.88 bytes/sec total size is 706609242 speedup is 1.42
首次传输过程进行完全备份,当再次运行该命令时,rsync 将只传输数据的增量。从而完成增量备份。
如果在客户端对服务器上的重要数据进行同步的话,可使用下列的命令:
# rsync -avzP --delete rsync@Server::CriticalData /Backup
这里调用 --delete 选项,表示客户端上的数据要与服务器端完全一致,如果 /Backup 目录中有服务器不存在的文件,则删除。从而保持客户端与服务器的数据同步。
注意:谨慎使用 --delete 选项,最好不要把已经有重要数所据的目录当做客户端的备份目录,否则会误删除重要数据。
如果用客户端的备份数据去恢复服务器,可使用下列的命令:
#rsync – avzPO /Backup/ rsync@Server::CriticalData
这里需要将 rsync.conf 中 read only 设置为 false,同时使 /CirticalData 目录具有写权限。
注意:也可调用 --delete 选项来保持客户端与服务器端的数据同步。在后面,将详细介绍 rsync.conf 的配置。-O 参数用于忽略目录的时间属性。
数据备份与同步的自动化实现
系统管理员必须执行的数据备份与同步任务大多牵涉到某种形式的系统配置,当管辖的任务比较庞大,数据量较多,但操作一样且有固定周期时,采用自动化脚本就成为必然。尤其是为多个操作系统提供支持时。
要实现自动化操作,脚本编制是必须掌握的基本技能。一个脚本由一系列命令构成,这些命令负责执行各种各样的任务。系统管理员在重复执行了几遍类似的命令后,通常就能准确地掌握要点,并希望利用脚本,将重复性的工作交给计算机去做。常用的脚本语言有 Shell,Perl,Tcl/Expect 等。
实用命令的自动化实现
本文的示例主要是通过 Shell 来实现的。Shell 是一种“解释性”语言,列出了管理员通过键盘敲入的相同命令, 并且每次执行一次这样的命令。
例如执行一条简单的 tar 命令,可以使用下面的一个简单的脚本。
tar -czvf backup.tar.gz /CriticalData/
清单 3. mksysb 自动化示例脚本
find /CriticalData/ -depth | cpio -ov > backup.cpio
清单 4. backup 自动化示例脚本
DATE=`date | awk '{ printf $1 }'` case $DATE in Mon) LEVEL=1;; Tue) LEVEL=2;; Wed) LEVEL=3;; Thu) LEVEL=4;; Fri) LEVEL=5;; Sat) LEVEL=6;; Sun) LEVEL=7;; esac
backup -$LEVEL -uf /dev/rmt0 /home
创建 rsync.conf 作为服务器配置文件
read only = true use chroot = true transfer logging = true log format = %h %o %f %l %b log file = /var/log/rsyncd.log pid file = /var/run/rsyncd.pid secrets file = /etc/rsyncd.secrets hosts allow = 192.168.0.0/255.255.255.0 max connections = 5 timeout = 300 motd file = /etc/rsyncd/rsyncd.motd
path = /CriticalData list = true ignore errors comment =This is Critical Data auth users = rsync secrets file = /etc/rsyncd/rsyncd.secrets exclude = Common/
指定该模块所定义的备份目录的路径,该参数是必须指定的。
用来指定多个由空格隔开的多个文件或目录 ( 相对路径 ),并将其添加到 exclude 列表中。这等同于在客户端命令中使用 --exclude 参数。一个模块只能指定一个 exclude 选项。但是需要注意的一点是该选项有一定的安全性问题,客户端很有可能绕过 exclude 列表,如果希望确保特定的文件不能被访问,那就最好结合 uid/gid 选项一起使用。 [NextPage]
auth users 该选项指定由空格或逗号分隔的用户名列表,只有这些用户才允许连接该模块。这里的用户不一定是客户端存在的用户。如果"auth users"被设置,那么客户端发出对该模块的连接请求时,需要对用户身份进行验证。用户的名和密码以明文方式存放在"secrets file"选项指定的文件中。默认情况下无需密码就可以连接模块 ( 也就是匿名方式 )。
#chmod 600 /etc/rsyncd/rsyncd.secrets
This is Critical Data Server =============================
将 rsync 启动
在客户端创建一个 /root/rsync/ 目录用来存放自动化脚本和其它文件。
export PATH=$PATH:/bin:/usr/bin:/usr/local/bin
SERVER=rsync@Server DIR=CriticalData
BDIR=/Backup BASE=Current INCREMENTDIR=`date +%Y-%m-%d`
EXCLUDES=/root/rsync/excludes LOG=/tmp/rsync.log
OPTS="-avz--force --delete --delete-excluded --exclude-from=$EXCLUDES -b --backup-dir=$BDIR/$INCREMENTDIR --ignore-errors"
install -d $BDIR/$BASE
run_rsync() { echo "==========Begin rsync: `date`===========" >>$LOG 2>&1 du -s $BDIR/* >>$LOG 2>&1 rsync $OPTS $SERVER::$DIR $BDIR/$BASE >>$LOG 2>&1 echo "==========End rsync: `date`===========" >>$LOG 2>&1 mail root -s "Backup Report" < $LOG rm $LOG }
if [ -f $EXCLUDES ]; then if [ -d $BDIR ]; then run_rsync else echo "cant find $BDIR"; exit fi else echo "cant find $EXCLUDES"; exit fi
/Backup # ls 2009-06-16 Current
如果系统管理员需要连续地定期地执行脚本,那么就需要借助 Unix/Linux 系统的 crontab 功能,使系统可以定期地调用 rsync.sh 脚本。
如果配置正确 , rysnc.sh 的执行过程将会邮寄给 root 用户,通过 mail 命令可读取这些邮件。
Mail version 8.1 6/6/93. Type ? for help. "/var/spool/mail/root": 1 message 1 new >N 1 root@cdlf2ler02.clus Tue Jun 16 16:53 32/1050 "Backup Report" &
From root@cdlf2ler02.clusters.com Tue Jun 16 16:53:35 2009 Date: Tue, 16 Jun 2009 16:52:14 -0400 From: root To: root@cdlf2ler02.clusters.com Subject: Backup Report
16 /Backup/Current =========================== This is Critical Data Server ===========================
receiving file list ... done deleting b/ ./ Location/ Name/ Name/Namelist1
total size is 3 speedup is 0.01 ==========End rsync: Tue Jun 16 16:52:14 EDT 2009===========
|
||||
| 最新热点 | 最新推荐 | 相关文章 | ||
| 讲解Linux服务器被黑解决方法 linux vm 添加硬盘 简单的Linux网吧电影服务器 Linux的日志文件系统简要剖析 Linux服务器:关于linux下磁盘空间无… Linux服务器:解决Linux磁盘空间满的… Linux中如何获得配置文件的绝对路径 详解Windows切至Linux的7大障碍 Linux系统Apache服务的信息查看模块… Linux之邮件服务器配置指南 |
| 设为首页- 关于我们 - 联系方式 - 版权声明 - 友情链接 - 网站地图 - |
| Copyright©2003-2010 45IT.COM All Rights Reserved. 浙ICP备05056851号 |

