| 当前位置: 电脑软硬件应用网 > 电脑学院 > 办公软件 > Excel > 正文 |
|
|||
| 让你从菜鸟成为Excel高手(二) | |||
| 2006-11-5 8:50:22 文/佚名 出处:eNet硅谷动力 | |||
|
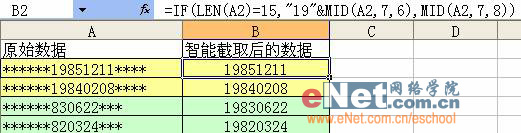
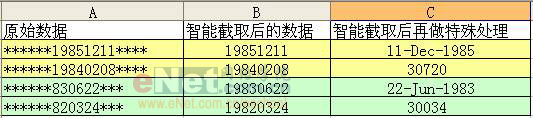
此招用来对原始数据进行截取。截取的方式是从第一个字符开始,截取用户指定长度的内容。 例如:在一个工作表中,某一列的资料是地址,录有省、市、街道等。如果你想插多一列,加入省份的资料,以便进行省份筛选,则可用该函数自动进行截取,而无需人工输入。 使用语法 LEFT(text,num_chars) Text 是包含要提取字符的文本字符串,可以直接输入含有目标文字的单元格名称。 Num_chars 指定要由 LEFT 所提取的字符数。 Num_chars 必须大于或等于 0。 如果 num_chars 大于文本长度,则 LEFT 返回所有文本。 如果省略 num_chars,则假定其为 1。 应用示例:  第六招:去头留尾(Right函数) 此招与上招刚好相反,截取的方式是从最后一个字符开始,从后往前截取用户指定长度的内容。 使用语法 RIGHT(text,num_chars) RIGHTB(text,num_bytes) Text 是包含要提取字符的文本字符串,可以直接输入含有目标文字的单元格名称。 Num_chars 指定希望 RIGHT 提取的字符数。 注意:Num_chars 必须大于或等于 0。 如果 num_chars 大于文本长度,则 RIGHT 返回所有文本。 如果忽略 num_chars,则假定其为 1。 应用示例: 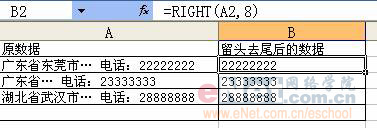 详细解释 公式“=Right(A2,8)”中A2表示要截取的数据为A2单元格的内容“广东省东莞市… 电话:22222222”,“8”表示从最后一位开始,共截取8个字符,因此系统返回“22222222”。尽管原始数据长短不齐,但我们只关心最后的8位电话号码。 第七招:掐头去尾(MID函数) 与上面的两招不同,此招既不从第一位开始截取,也不从最后一位开始截取,而是由用户自行指定开始的位置和字符的长度。因此,若用户指定从第一位开始,便和Left函数一样。 使用语法 MID(text,start_num,num_chars) Text 是包含要提取字符的文本字符串,可以直接输入含有目标文字的单元格名称。 Start_num 是文本中要提取的第一个字符的位置。文本中第一个字符的 start_num 为 1,以此类推。 Num_chars 指定希望 MID 从文本中返回字符的个数。 注意: 如果 start_num 大于文本长度,则 MID 返回空文本 ("")。 如果 start_num 小于文本长度,但 start_num 加上 num_chars 超过了文本的长度,则 MID 只返回至多直到文本末尾的字符。 如果 start_num 小于 1,则 MID 返回错误值 #VALUE!。 如果 num_chars 是负数,则 MID 返回错误值 #VALUE!。 如果 num_bytes 是负数,则 MIDB 返回错误值 #VALUE!。 应用示例:  详细解释 公式“=MID(A2,7,8)”中A2表示要截取的数据为A2单元格的内容“******19851221****”,“7”表示从第7位开始,共截取8个字符,因此系统返回用户想截取的生日时间“19851221”。 OK,我们己经学了三招,但读者可能己经发现,实际工作中,原始资料并不会如此整齐地出现,让我们很容易的用上面的三招去截取。比如说,第三招示例中,我用的都是18位的身份证号码,但实际上,很多人仍在使用15位的身份号码,这样一来,因原始数据长度不一致,导致在截取时,便会截错。再如我们的第一个例子,我们截的是3位,但实际中,有的省份名称本身就有3位,因此对这种情况,简单的套用就无法取得正确的内容。 如我在第一篇中所说,在实际的工作使用中,单一公式常常都是不够的,而需要使用组合招数。例如刚才的身份证号码不同长度问题,我们可以在招式中,加入对位数的判断,如果长度是18位,则取8位,如果是15位的,则取6位。还记得前面我们学过左右逢源吗?这一招可是相当的实用哦,我们经常会用到。另外,下面我再介绍两招,用来对单元格的内容进行判断。一个是“瞎子摸象”(Find函数),让用户对单元格内容中指定的字符进行定位,以确认其位置。当位置被确认后,截取就是轻而易举的一件事情了。另一招是“鲁班神尺” (Len函数),让用户对单元格内容的长度进行测量,得出其长度后,再做相应的截取处理。 第八招:瞎子摸象(Find函数) 此招用来对原始数据中某个字符串进行定位,以确定其位置。因为该招进行定位时,总是从指定位置开始,返回找到的第一个匹配字符串的位置,而不管其后是否还有相匹配的字符串,有点像瞎子摸象,摸到哪就说哪,因此取名“瞎子摸象”。 使用语法 FIND(find_text,within_text,start_num) Find_text 是要查找的文本。 Within_text 是包含要查找文本的文本。 Start_num 指定开始进行查找的字符。within_text 中的首字符是编号为 1 的字符。如果忽略 start_num,则假设其为 1。 注意: 使用 start_num 可跳过指定数目的字符。例如,假定使用文本字符串“AYF0093.YoungMensApparel”,如果要查找文本字符串中说明部分的第一个“Y”的编号,则可将 start_num 设置为 8,这样就不会查找文本的序列号部分。FIND 将从第 8 个字符开始查找,而在下一个字符处即可找到 find_text,于是返回编号 9。FIND 总是从 within_text 的起始处返回字符编号,如果 start_num 大于 1,也会对跳过的字符进行计数。 如果 find_text 是空文本 (""),则 FIND 则会返回数值1。 Find_text 中不能包含通配符。 如果 within_text 中没有 find_text,则 FIND返回错误值 #VALUE!。 如果 start_num 不大于 0,则 FIND返回错误值 #VALUE!。 如果 start_num 大于 within_text 的长度,则 FIND 返回错误值 #VALUE!。 应用示例:  上图中,对含有不同地方的数据,利用“Find”函数,非常简单地确定了“省”出现的位置。 详细解释 公式“=FIND("省",A2)”中,“省”表示要查找的文本为“省”,(实际使用中,也可以很长的一串字符)。要找查找的对象是A2单元格的内容“广东省东莞市东城区…”,因为没有指定起始位置,所以系统从第一位开始。返回的“3”,表示“省“字在第三位。而“黑龙江省哈尔滨市…”则返回4。 与Find类似,Search函数也有相同的功能。它们的区别是,Find区分大小写,而Search不分大小写(当被查找的文本为英文时)。 另外,在Excel中,对文本进行处理的很多函数都提供了一个特别用来处理双字节字符(如中文,日文)的函数,一般是在原函数后加“B”,如FIND, 就有一个FINDB。之前讲过的LEFT,相对应的就是LEFTB等。其实,我们在实际应用中,使用不带“B”的函数就足够了。如果你想使用带“B”的函数,则要特别注意,尤其是在组合运用函数时,其中一个函数使用带“B”的形式,则其它有带“B”形式的函数,全部都要使用其带“B”的形式,否则结果极可能是错的。 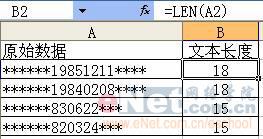
 |
|||
| 最新热点 | 最新推荐 | 相关文章 | ||
| 让你从菜鸟成为Excel高手(一) |
| 关于45IT | About 45IT | 联系方式 | 版权声明 | 网站导航 | |
|
Copyright © 2003-2011 45IT. All Rights Reserved 浙ICP备09049068号 |